Given a binary tree, return the level order traversal of its nodes’ values. (ie, from left to right, level by level).
For example:
Given binary tree [3,9,20,null,null,15,7],
1 | 3 |
return its level order traversal as:
1 | [ |
Accepted
1 | /** |
Given a binary tree, return the level order traversal of its nodes’ values. (ie, from left to right, level by level).
For example:
Given binary tree [3,9,20,null,null,15,7],
1 | 3 |
return its level order traversal as:
1 | [ |
1 | /** |
Given a 3 x 3 matrix, find if there exists a sum of numbers from each row that adds up to a given number such as 0.
Example:
1 | [ |
Example
1 | [ |
The approach I thought of and was recomended was to try and find a O(n^2) alternative, since this is one of those problems that is not possoible to do in better time. The way we can do this is to recognize that we are looking for a sum of three numbers (one from each row) and that can be either 0 or less than 0 or more than 0. If we simply pick each element in derial order that degenerates into cubic complexity. But what if we sorted each row. Let’s take an example:
1 | [ |
Leetcode seems to have a similar problem here
1 | class Solution { |
This fails the test case because we are allowing duplicates when we shouldn’t.
1 |
|
1 | class Solution { |
This has a side effect and fails the following test case
1 | Input: [-1,0,1,2,-1,-4] |
The condition (nums[i]+nums[j+1]+nums[k] > sum should be in an else if
1 | class Solution { |
However, this fails the testcase
1 | Input: [1,-1,-1,0] |
The issue is that since we are sorting in ascending order and we have the check to skip duplicates of nums[i], we end up skipping all the -1’s!
We need to modify that check a bit.1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30class Solution {
public:
vector<vector<int>> threeSum(vector<int>& nums) {
vector<vector<int>> res;
if (nums.size() < 3) return res;
sort(nums.begin(), nums.end(), [](int a, int b) { return a < b;});
for (int i = 0; i < nums.size() - 2; i++) {
// skip duplicates of nums[i]
if (i+1 < nums.size() && nums[i] == nums[i+1]) { continue; }
int j = i + 1;
int k = nums.size() - 1;
while (j < k) {
int sum = nums[i]+nums[j]+nums[k];
if (sum == 0) {
res.push_back({nums[i], nums[j], nums[k]});
// skip all duplicates for nums[j] and nums[k]
while (j < k && nums[k-1] == nums[k]) k--;
while (j < k && nums[j+1] == nums[j]) j++;
j++;
k--;
} else if (nums[i]+nums[j+1]+nums[k] > sum) {
k--;
} else {
j++;
}
}
}
return res;
}
};
But this fails
1 |
|
Ah this brings us back to the previous failure.
I think I misunderstood. The only duplicates we should skips for nums[i] are 0’s?
1 | class Solution { |
The main comparison logic is somewhat flawed. We need to check if sum is equal to 0, greater than 0 or less than 0. The reason fos this is that
1 | class Solution { |
1 | throw std::invalid_argument("can't resolve ifindex for main intf"); |
https://stackoverflow.com/questions/7627098/what-is-a-lambda-expression-in-c11
emplace_back() vs push_backemplace_back:
I am being constructed.
push_back:
I am being constructed.
I am being moved.
Computes distance between iterators
1 | std::distance(words_begin, words_end) |
is_sorted_until()Returns an iterator to the first element in the range [first,last) which does not follow an ascending order.
is_sorted()Returns true if the range [first,last) is sorted into ascending order.
You have n super washing machines on a line. Initially, each washing machine has some dresses or is empty.
For each move, you could choose any m (1 ≤ m ≤ n) washing machines, and pass one dress of each washing machine to one of its adjacent washing machines at the same time .
Given an integer array representing the number of dresses in each washing machine from left to right on the line, you should find the minimum number of moves to make all the washing machines have the same number of dresses. If it is not possible to do it, return -1.
Example1
Input: [1,0,5]
Output: 3
Explanation:1
2
31st move: 1 0 <-- 5 => 1 1 4
2nd move: 1 <-- 1 <-- 4 => 2 1 3
3rd move: 2 1 <-- 3 => 2 2 2
Example2
Input: [0,3,0]
Output: 2
Explanation:1
21st move: 0 <-- 3 0 => 1 2 0
2nd move: 1 2 --> 0 => 1 1 1
Example3
Input: [0,2,0]
Output: -1
Explanation:
It’s impossible to make all the three washing machines have the same number of dresses.
Note:
The range of n is [1, 10000].
The range of dresses number in a super washing machine is [0, 1e5].
Suppose LeetCode will start its IPO soon. In order to sell a good price of its shares to Venture Capital, LeetCode would like to work on some projects to increase its capital before the IPO. Since it has limited resources, it can only finish at most k distinct projects before the IPO. Help LeetCode design the best way to maximize its total capital after finishing at most k distinct projects.
You are given several projects. For each project i, it has a pure profit Pi and a minimum capital of Ci is needed to start the corresponding project. Initially, you have W capital. When you finish a project, you will obtain its pure profit and the profit will be added to your total capital.
To sum up, pick a list of at most k distinct projects from given projects to maximize your final capital, and output your final maximized capital.
Example 1:
Input: k=2, W=0, Profits=[1,2,3], Capital=[0,1,1].
Output: 4
Explanation: Since your initial capital is 0, you can only start the project indexed 0.
After finishing it you will obtain profit 1 and your capital becomes 1.
With capital 1, you can either start the project indexed 1 or the project indexed 2.
Since you can choose at most 2 projects, you need to finish the project indexed 2 to get the maximum capital.
Therefore, output the final maximized capital, which is 0 + 1 + 3 = 4.
Note:
You may assume all numbers in the input are non-negative integers.
The length of Profits array and Capital array will not exceed 50,000.
The answer is guaranteed to fit in a 32-bit signed integer.
We would like to maximize the profit of each investment at each step to get the best overall profit. This suggests a greedy approach.
1 | class Solution { |
We need to ensure we check if best,first
1 | class Solution { |
Time limited exceeded on this solution. ⏲
How can we optimize this?
##1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33class Solution {
struct elem_t {
int p; //profit
int c; //capital
};
public:
int findMaximizedCapital(int k, int W, vector<int>& Profits,
vector<int>& Capital) {
int len = Profits.size();
vector<elem_t> v(len);
for (int i = 0; i < len; i++) {
v[i] = {Profits[i], Capital[i]};
}
sort(v.begin(), v.end(),
[](const elem_t& a, const elem_t& b) {
return a.p > b.p;
});
for (int i = 0; i < k; i++) {
auto it = v.begin();
auto selected = it;
for (; it != v.end(); it++) {
if ((*it).c <= W) {
selected = it;
break;
}
}
W += (*selected).p;
v.erase(selected);
}
return W;
}
};
1 |
|
The inefficiency is a result of us using erase() as seen here
“Because vectors use an array as their underlying storage, erasing elements in positions other
than the vector end causes the container to relocate all the elements after the segment
erased to their new positions. This is generally an inefficient operation compared to the one
performed for the same operation by other kinds of sequence containers (such as list or
forward_list).”
I was afraid of that! Guess checking documentation is a good idea. 😖
Let’s try to use a set to track what projects we have already selected. We can track via addresses of array elements.
1 |
|
Um….this one times out! 😰
So, using the set is not as helpful as I thought.
Spread out requests across several servers, each of which maintains a replica of our application server.
Each DNS request can be used to send a different IP address. So each new request will go the next available sever. Can use something like BIND(Berkely Internet Name Daemon). Google uses something like this?
1 | ________________ |
Reference
More about HTTP Headers
Load balancing concepts
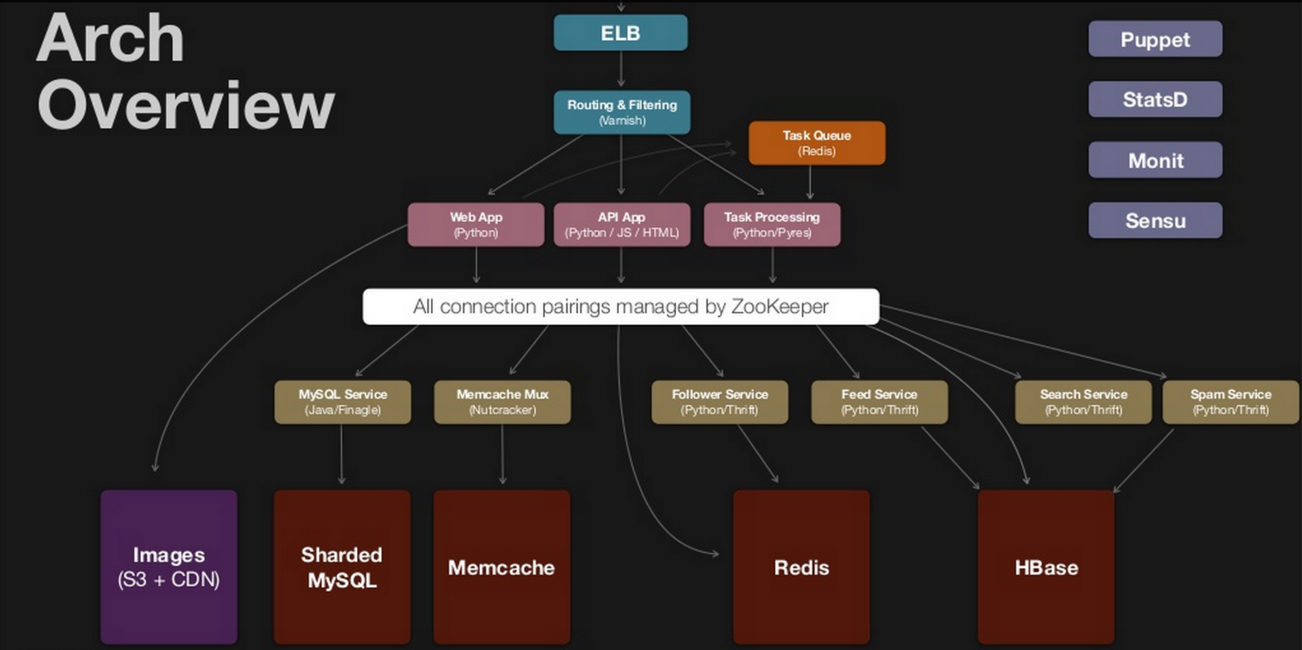
Aman many more good ones at QCON!
Given a non-empty array of integers, return the third maximum number in this array. If it does not exist, return the maximum number. The time complexity must be in O(n).
Example 1:
Input: [3, 2, 1]
Output: 1
Explanation: The third maximum is 1.
Example 2:
Input: [1, 2]
Output: 2
Explanation: The third maximum does not exist, so the maximum (2) is returned instead.
Example 3:
Input: [2, 2, 3, 1]
Output: 1
Explanation: Note that the third maximum here means the third maximum distinct number.
Both numbers with value 2 are both considered as second maximum.
1 | class Solution { |
Oops! Read the question carefully.
If it does not exist, return the maximum number.
1 | class Solution { |
There still a problem with this!
For [3,2,3]we see m1 = 3, m2 = 3,m3 = 2! 😱
We should have seen m1 = 3, m2 = 2,m3 = INT_MIN!
1 | class Solution { |
Well this fails the testcase below.
1 | Input: [1,2,2,5,3,5] |
The reason is because we need to ensure we check both m1 and m2!
1 | class Solution { |
Oh great. Now it fails here… 🤕
Ah you got me there!
1 |
|
Well we have no way of knowing right now that the m3 was set to INT_MIN or was never updated.
If we has used a data structure like a set this might have been simpler and cleaner.
Well we can possibly use a flag to denote when all variables have been touched and when they have not. Then we also need to test >= as opposed to >.
1 | class Solution { |
This is not a good approach.
Let’s go back and think about the requirement a bit more. Well the numbers are ints. So we cannot initialize to INT_MIN. 🤔
OK so what can we initialize this to?
How about LONG_MIN 💡!
1 | class Solution { |
Nice 👍
But this has an obvious shortfall. What if the inputs are long? Well we can use long long?
But you see the limitations.
A set would be cleaner.
Given a sorted linked list, delete all nodes that have duplicate numbers, leaving only distinct numbers from the original list.
Example 1:
Input: 1->2->3->3->4->4->5
Output: 1->2->5
Example 2:
Input: 1->1->1->2->3
Output: 2->3
We try and use a pointer to a pointer. This allows handling special cases like updating head more generically although the approach may be off-putting to some.
Trying it on paper with a picture paid off. There wasn’t even a compilation error 🕺
1 | /** |
There is a flaw in this solution though. Can you see it?
That skipDups() function only skips but doesn’t release any memory!
1 | class Solution { |