Post Order
First iteration
1 | /* |
Recursive
Preorder
todo
Inorder
todo
1 | /* |
todo
todo
1 | 4-3+6-(45+6-(77 - 5) + 3) is equivalent to |
So we can keep track of the sign changes
1 |
|
1 |
|
TODO
O(n)1 | /** |
1 | /** |
1 | /** |
1 | class Solution { |
While the above solution is functional, it’s pretty long. We can remove the need for the special case of the val being at the head by using some pointer magic.
TODO: add picture
1 | class Solution { |
We need to set the lower and upper bounds as per given indices.
Example:
1 | for given example |
matrix is immutable
1 | class NumMatrix { |
While the solution above is in the right spirit. The execution suffers.
(0 <= row1 < rsize) are erroneous.1 | class NumMatrix { |
https://leetcode.com/problems/decode-string/description/
1 | Input: |
It’s really important to try several types of examples out before we jump into the final solution. One important point to note is that we need to keep passing in pos as a reference it needs to be shared across all function invocations since we are moving through the string in one pass and need to keep track of the number of characters consumed. The solution below is a step in the right direction but has some flaws as noted below.
1 | class Solution { |
decodeString() doesn’t need that ugly logic. We can just call parse().if (s[pos++] == ']' is incorrect here since it will increment position and then check the value, which is hardly what we want.1 | class Solution { |
1 | /** |
The problem with the above solutions is that it doesn’t work for cases like the following where a number smaller than root appears on the right even though the sub-tree is a valid BST.
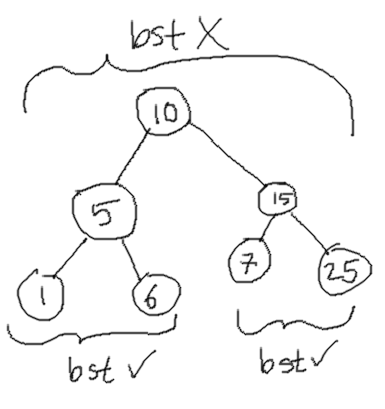
Since the approach above is incomplete, let’s think of what a proper BST looks like.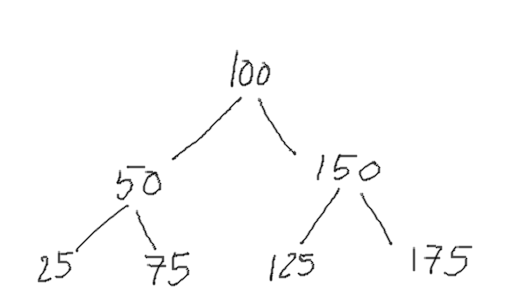
If we perform an inorder traversal of this we see that the numbers are all in ascending order.1
25,50,75,100,125,150,175
So…we can do an inorder traversal and ensure that at any point when we visit a node the last node we visited has the smaller value!
1 | /** |
It’s important to keep a track of the pointer since we need to know when the left most node is hit. If we pre-populate with min value such as int prev_val = MIN_INT; then that will not work in some cases when MIN_INT is actually a value of the tree. Can you see how?
Tree traversals can be done both using recursive and iterative approaches. Recursive solutions may be more intuitive but they suffer from the possibility of stack overflow. I will plan to have a separate post comparing each of the traversals using both approaches.
1 |
|
1 | int dfs(string start, string end, vector<string>& bank, int tries) { |
Unfortunately, there is a major flaw in the logic above. The problem is that we are only flipping the letters as per the end string. This worked in the example I chose above, but there may be paths we have not considered. This means we may not always find the path to the end string.
We should flip letters to {A, C, T, G} and not just the ones we want to change for the end string.
1 | keep a visited vector of booleans to denote when we have visited a particular string from the bank |
Buggy solution below1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31int minMutation(string start, string end, vector<string>& bank) {
unordered_set<string> V; // visited
unordered_set<string> B; // bank
vector<string> Q; // work queue
vector<char> letters = {'A', 'C', 'G', 'T'};
// copy strings from bank to set for quicker lookup
for (auto e: bank) {
B.push_back(e);
}
Q.push_back(start);
while (!Q.empty()) {
string s = Q.front();
Q.erase(Q.begin());
level++;
if (s == end) return level;
for (int i = 0; i < s.size(); i++) {
char c = s[i];
for (auto l: letters) {
s[i] = l;
if (!V.find(s) && B.find(s)) {
Q.push_back(s);
}
s[i] = c;
}
}
}
return -1;
}
FIxed
1 | class Solution { |
Suppose an array sorted in ascending order is rotated at some pivot unknown to you beforehand.
1 | (i.e., [0,1,2,4,5,6,7] might become [4,5,6,7,0,1,2]). |
Find the minimum element.
You may assume no duplicate exists in the array.
1 | Example 1: |
1 | - no dups |
The following is a O(n) solution
1 | int findMin(vector<int>& nums) { |
There is a O(logn) solution that uses binary search!
Given a 2D board and a word, find if the word exists in the grid.
The word can be constructed from letters of sequentially adjacent cell, where “adjacent” cells are those horizontally or vertically neighboring. The same letter cell may not be used more than once.1
2
3
4
5
6
7
8
9
10
11
12Example:
board =
[
['A','B','C','E'],
['S','F','C','S'],
['A','D','E','E']
]
Given word = "ABCCED", return true.
Given word = "SEE", return true.
Given word = "ABCB", return false.
1 | DFS would be te desired approach. |
1 | bool dfs(vector<vector<char>>& board, string word, int i, int j, int p) { |
This works for most cases but here is an example where it fails 😧
1 | board = [["a"]] |
We need to consider the case of single letter words.1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39bool dfs(vector<vector<char>>& board, string word, int i, int j, int p) {
if ((i < 0) || (j < 0) || (i >= board.size()) || (j >= board[0].size())) return false;
if (p >= word.size()) return true;
if (word[p] == board[i][j]) {
char c = board[i][j];// for caching currently inspected char
//cout << "checking " << c << endl;
board[i][j] = 0;//erase temporarily to mark as visited
// check top neighbor
//cout << "check top\n";
if (dfs(board, word, i - 1, j, p+1)) return true;
// bottom
//cout << "check bottom\n";
if (dfs(board, word, i + 1, j, p+1)) return true;
// left
//cout << "check left\n";
if (dfs(board, word, i, j - 1, p+1)) return true;
//right
//cout << "check right\n";
if (dfs(board, word, i , j + 1 , p+1)) return true;
if (word.size() == 1) return true;
// we need to restore char at end of each run
board[i][j] = c;
}
return false;
}
bool exist(vector<vector<char>>& board, string word) {
for (int i = 0; i < board.size(); i++) {
for (int j = 0; j < board[0].size(); j++) {
if (dfs(board, word, i, j, 0)) return true;
}
}
return false;
}
Given an integer array, find three numbers whose product is maximum and output the maximum product.1
2
3
4
5
6
7
8
9
10
11
12
13
14
15Example 1:
Input: [1,2,3]
Output: 6
Example 2:
Input: [1,2,3,4]
Output: 24
Note:
The length of the given array will be in range [3,104] and all elements are in the range [-1000, 1000].
Multiplication of any three numbers in the input won't exceed the range of 32-bit signed integer.
1 | 3 * 2 = 3 + 3 OR 2 + 2 + 2 |
1 | int maximumProduct(vector<int>& nums) { |
This solution is longer than it needs to be (and also seems to fail for some corner test cases).
A simpler approach is as follows:
1 | if (nums.size() == 3) return (nums[0]*nums[1]*nums[2]); |
This is a nlog(n) approach.
It is possible to do this in O(n).